
Introduction
SCTE-35 is a standard to signal an advertisement (ad) insertion opportunity in a transport stream. This relatively short standard document is, however, difficult to understand without the insight of ad insertion workflow. This article explains the standard text with some background and context information.
Most TV programs make money by selling ad time slots to the advertisers. For example, 30 second ad time slot of Super Bowl 2014 was sold for $4 million.
Ads are not hard coded into the TV program. Instead, the broadcasters insert the ad to the time slot on the fly. This allows broadcasters to change ad based on the air time, geographic location, or even personal preference. All we need is a special marker in the broadcast stream to signal the ad time slots.

Analog broadcasting used a special audio tone called DTMF to signal the ad time slot. In digital broadcasting, we use SCTE-35.
SCTE-35 packets are multiplexed with video and audio packets in the transport stream. The syntax of the payload is called splice_info_section(). The syntax signals one of six commands. The most important command is splice_insert() and I explain it first.
Splice Insert Command

splice_insert signals a splice event. When out_of_network_indicator is 1, it signals switching from the network program to an advertisement. When out_of_network_indicator is 0, it signals switching back to the network program. Although not formally defined in the standard, these events are often called cue-out event and cue-in event respectively.

The timing of the splice event is specified in terms of PTS. It uses two fields; pts_adjustment field in splice_info_section() syntax and pts_time field in splice_insert() syntax. The splice event PTS is calculated as 

Many ad time slots have a fixed duration such as 15, 30, and 45 seconds. Instead of explicitly signaling cue-in event, you can use break_duration() syntax to specify duration of the time slot in the cue-out event. When auto_return field is 0, the signaled duration is interpreted as “informative” and you still have to signal cue-in event. When auto_return field is 1, the devices terminates the break after the specified duration without a cue-in event. Note that you can always overwrite the break duration by signaling cue-in event explicitly.
It is also possible to signal a splice event without specifying the time. When splice_immediate_flag is 1, a splice event is triggered at the earliest possible timing. This, however, causes various headaches in practice. For example, when you have redundant systems to produce same broadcast streams, “Immediate” might result in slightly different timing on each system due to the command delivery latency. SCTE-35 recommends to use splice_immediate_flag = 1 only for early termination of ad breaks.
Splice Schedule Command
Another command to explain is splice_schedule(). It has similar syntax and semantic as splice_insert() but it uses wallclock time instead of PTS. This allows to schedule the ad breaks far before the actual event based on the broadcast schedule and wall clock time. On the other hand, wallclock time has only second precision and not suitable for frame accurate splicing.
It is worth noting that the wallclock time uses so called GPS time. For engineers who are familiar with C/C++ time function such as time(), GPS time is different in two important ways.
- The epoch is 1980/01/06T00:00:00Z instead of 1970/01/01T00:00:00Z.
- Leap seconds are counted instead of skipped. As of today, there are 16 leap seconds since 1980/01/06. Therefore, GPS time looks 16 seconds ahead of the wall clock time we are familiar with.

The leap second problem can be hard in some use cases. Since leap second is unpredictable, we need to look up the latest leap second information published by IERS. A correct way is to read GPS_UTC_offset value encoded in PSIP metadata carried in ATSC stream. However, not every system has access to the information. SCTE-35 allows implementation to ignore the leap second but it results in about 16 second error.
Splice Event Repetition and Cancellation
Both splice_insert and splice_schedule commands are issued with a unique identifier of each splice event. The identifier is 32 bit integer and usually incremented for each event.

You might wonder how to ensure the uniqueness of splice_event_id for long running 24/7 live event. It is 32 bits integer. Even if we have splice event for every second, we won’t running out of the number for 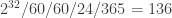
One use case of splice_event_id is redundant repetition. As transport stream packets are often delivered over unreliable network, it is recommended to send splice_insert command multiple times with a same splice_event_id before the actual event. Another use case is a cancellation. You can cancel an event by specifying the splice_event_id and set splice_event_cancel_indicator to 1. You can also override an event by inserting a new one after cancellation. To prevent a race condition, it is required to finalize the splice_event 4 second before the actual event.
Segmentation
SCTE-35 was originally designed for ad insertion. However, it turned out to be also useful for more general segmentation signaling.
Consider a movie program. The program may have one or more “chapters” as you see on DVD. Some parts of the program are reserved for provider ads such as announcement of TV drama to broadcast tonight. Within that time slot, some parts may be reserved for the local ads.
Depending on the distribution method (TV, Web, DVR recording, etc), the provider may want to make only the selected part of the program available for legal reasons.
Also, each segment may have associated identifier such as TMS ID, AD-ID, and ATSC content identifier. These identifiers are collectively called UPID (Unique Program Identifier) and would be useful for content management purpose.

Such hierarchical structure cannot be signaled by splice_insert syntax. Also, splice_insert is not sufficient to carry various metadata such as restrictions and UPID. The SCTE-35 segmentation descriptor addresses the problem.
Segmentation is signaled by a combination of time_signal command and segmentaiton_descriptor. The time_signal command simply signals a timestamp of the segmentation.

The complex matter is all taken care by segment descriptor.

The red part describes various restrictions based on the delivery method. For example, you can make the segment not available for Web delivery.
The blue part carries UPID which identifies the content of the segment. For example, you can identify a segment to be “Gone with the wind” by looking up UPID (ISAN number) encoded in the SCTE-35 message.
The structure of segmentation is similar to splice event except one important difference. In splice event, splice_event_id identifies each splice event, i.e. cue-out and cue-in have different splice_event_id. On the other hand, segmentation_event_identifier identifies one entire segment. This allows segments to be nested and make hierarchical structure.

SCTE-35 on over the top delivery
SCTE-35 is specific to a transport stream which is mainly used for traditional broadcasting context. As Web based video delivery becomes popular, many companies try to make something similar to SCTE-35 for Web delivery. For example, one attempt can be seen in a proprietary extension to HLS media playlist m3u8 format for ad insertion.
Although it is difficult to predict the future, I think all these proprietary ad marker technologies are to be faded out and the industry trends is moving in favor of using SCTE-35 as the ad marker data model. For example, a company uses XML representation of SCTE-35 as Web video ad marker. Another company uses base-64 encoded SCTE-35 splice_info_section syntax as an adaptive bit rate streaming ad marker. This is because they don’t want to lose any information of SCTE-35, which is matured and well supported by various devices, on the way from the content management system to cable network to Web delivery.
 . It means we still have more than 20% chance of the bug existing also in the previous version.
. It means we still have more than 20% chance of the bug existing also in the previous version.























 . Also suppose each developer downloads the source tree 4 times a day, which is 100 times per week as
. Also suppose each developer downloads the source tree 4 times a day, which is 100 times per week as 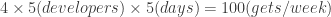 .
. 
 ,
, 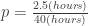 , and
, and  , thus
, thus

 , which is
, which is 


 , the waste ratio is about
, the waste ratio is about  , which is 1.56%.
, which is 1.56%.


")
")
 with init_cpb_removal_delay")

")
